Af Bjørn Axelsen, Lead Consultant hos Devoteam
Er der grund til at være skeptisk, når talen falder på at automatisere tidskrævende ESDH-/ECM-opgaver med AI? Vi har gennemført et par pilotprojekter for at få klarhed over, hvor langt det er muligt at gå. Resultaterne er lovende, men de gør det samtidig tydeligt, at teknologien har sine begrænsninger.
Mange steder er det en kamp at finde tid til journalisering og god sagsbehandling. Vi satte os for at undersøge, om det er muligt at få en hjælpende hånd fra AI ved at automatisere nogle af de tidskrævende opgaver. Eller måske blot lette medarbejdernes arbejde ved at lade AI komme med gode forslag, som medarbejderen manuelt kan godkende.
I denne artikel beskriver vi to pilotprojekter, hvor vi undersøger brug af AI til 2 ting:
1) automatisk kategorisering
2) automatisk tjek af brevtekster mod en tjekliste.
Projekterne afslører, at AI faktisk klarer opgaverne ganske godt, da vi opnår 90% – 100% træfsikkerhed. Det blev også tydeligt, at det sker uden varsel, når AI-teknologien skyder ved siden af. Derfor er det nødvendigt at overvåge den.
Pilotprojekt 1: Klassifikation og andre metadata for vilkårlige dokumenter
I det første pilotprojekt undersøgte vi, hvor effektivt AI kan læse et dokument og dernæst:
| ChatGPT og Large Language Models AI omfatter mange forskellige teknologier. Her undersøger vi ChatGPT, som er en stor sprogmodel (”Large Language Model”). ChatGPT er allerede trænet op til at forstå almindeligt sprog – i modsætning til de fleste andre AI-teknologier – og den kan derfor bruges til mange typer opgaver, uden at man først skal træne den op på en omfattende mængde dokumenter. |
- skrive en titel og et resumé
- klassificere det i forhold til en journalplan (liste med emner)
- tilføje emneord
- udtrække sagsparter.
Mange virksomheder anvender Sharepoint 365 og Teams til dokumenter. Det er to populære værktøjer, der deler den samme bagvedliggende motor for lagring af dokumenter. De spiller sammen med Power Automate, der er et værktøj til at automatisere processer. Vi har derfor taget udgangspunkt i dokumenter i Sharepoint 365 og lavet en integration til ChatGPT med Power Automate.
Som det første har vi lavet en helt simpel journalplan i en Sharepoint-liste:
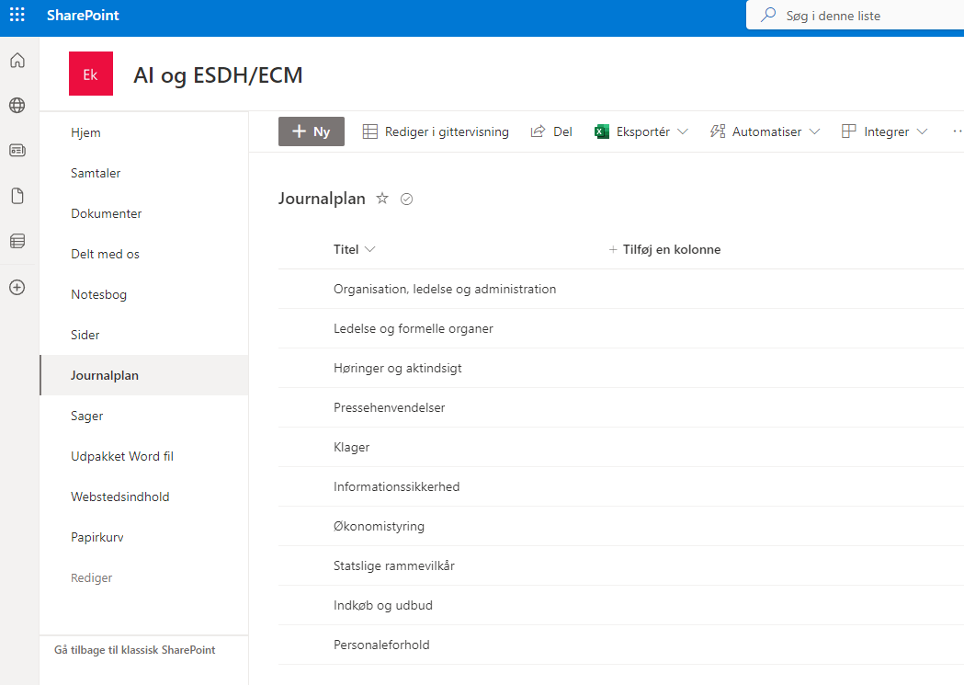
Dernæst har vi lavet en Sharepoint-dokumentliste, hvor der er forberedt felter til metadata:
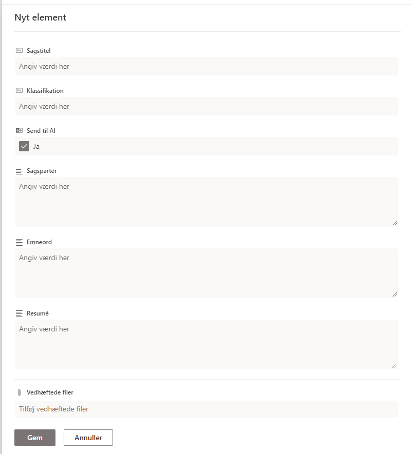
Når man lægger et dokument op i listen, aktiverer det automatisk et ”Power Automate flow”. Det består af en række af handlinger, som vi anvender til at få AI-tjenesten ChatGPT til at generere metadata for dokumenterne:

Oplysningerne fra AI føres til sidst tilbage til Sharepoint:

Hvor korrekt kan AI gøre det?
På et sæt med 20 tilfældige dokumenter lavede vi en vurdering af, om præcisionen var “god nok” for hvert enkelt dokument. Resultatet af vores vurdering blev følgende:
- Titel og et resumé: 100%
- Klassificering: 90%
- Emneord: 100%
- Sagsparter: 90%
Umiddelbart var det overraskende godt, omend det også viste nogle interessante begrænsninger, som vi gennemgår i det følgende.
Kun letforståelige klassifikationer
Vi har i pilotprojektet lavet en simpel og letforståelig journalplan. Vi kunne formentlig have opnået et endnu bedre resultat, hvis vi havde givet vores AI en mere grundig forklaring til de enkelte klassifikationer.
Det blev samtidig tydeligt for os, at vores fremgangsmåde ikke var helt skidt. Havde journalplanen rummet delvist overlappende ord, indeholdt mere specielle ord eller forudsat mere kontekstspecifik baggrundsviden, ville vi have opnået et dårligere resultat og i værste tilfælde et resultat, der ikke kunne bruges.
Hvorvidt en journalplan egner sig til en automatisk klassifikation med AI, afhænger derfor af en vurdering – og måske en test af den enkelte journalplan.
Læs også: AI kan blive din nye, trofaste ESDH-/ECM-assistent
AI vil hellere lyve end være i tvivl
Vi prøvede at lægge et dokument op, som ikke matchede noget i journalplanen. Her opfandt vores AI blot en ekstra klassifikation, selvom det ikke var en del af instruktionen. Det var ikke meningen. Her ville vi hellere have haft en besked om, at opgaven skulle til manuel behandling.
Lige i denne situation ville vi kunne fange problemet gennem et automatisk tjek: I slutningen af vores Power Automate Flow kunne vi tjekke, at ChatGPTs forslag til klassifikation rent faktisk eksisterede i journalplanen og i modsat fald markere, at der var sket en fejl, som kræver manuel behandling.
Men det illustrerer rigtig godt, hvordan AI sprogmodeller arbejder: hvis de ikke er i stand til at løse opgaven, finder de selv på noget. Det er naturligvis en udfordring, når kvaliteten skal være i orden.
Sagsparter kan være tricky
I en skriftlig klage over TV 2, som vi havde fundet på nettet, udtrak vores AI den ene sagspart som ”TV 2|DANMARK A/S”. Det var sådan modtageren var adresseret i starten af klagen. I selve klageteksten optrådte TV 2 både som ”TV 2” og ”TV 2|DANMARK A/S”. På den måde giver det mening at ChatGPT i valget mellem de to muligheder vælger den, som er mest fremtrædende.
I forbindelse med lige netop dette klagebrev gik vi lidt videre. Vi spurgte ChatGPT, hvem den indklagede var? Her svarede den først ”TV 2 DANMARK A/S (for reklame for Fleggaard/OMO)”. Da vi indskærpede, at den kun måtte svare med 1 indklaget uden yderligere detaljer, svarede den ”TV 2 DANMARK A/S”.
Dette var det rigtige svar dog med en lille variation i tegnsætning.
Resultatet gjorde os opmærksom på, at hvis vi ønsker at arbejde systematisk med sagsparter, så vi hurtigt kan udtrække alt, hvad der berører en bestemt person eller juridisk enhed, er det nødvendigt at efterbearbejde ChatGPTs forslag og samordne de forskellige stavemåder.
Begrænset længde af tekster
ChatGPT har sine begrænsninger, når det kommer til hvor store tekster, det er muligt at behandle på én gang. Derfor var vi nødt til at skære de sidste sider af dokumenterne fra, hvis de var meget lange. I vores prototype gav det ikke mærkbare kvalitetsforringelser. Det vil det dog kunne give i andre sammenhænge. Især hvis du vil have AI til at behandle et sagskompleks samlet – eksempelvis for at generere et sagsoverblik.
I skrivende stund (november 2023) kan ChatGPT behandle dokumenter på ca. 25 – 50 sider i én arbejdsgang. Har du længere dokumenter eller sagskomplekser, kan du få ChatGPT til først at fordøje dokumenterne i bidder. Derefter får du den til at udtrække resumeer og metadata på indholdet for så til sidst at samle det hele.
Grænsen for hvor store dokumenter AI kan forholde sig til på én gang, flytter sig hastigt. I løbet af nogle år er det formentlig ikke længere et problem.
Pilotprojekt 2: AI-kontrol af breve ud fra tjekliste
Når virksomheder eller myndigheder skriver et brev, vil de gerne sikre, at modtageren let kan forstå brevet, og at der ikke er juridiske uklarheder i brevet.
Tjeklister er en måde at opnå det på. I nogle tilfælde er der oplysninger, som skal fremgå af brevet, og der kan være krav til formuleringer i brevet.
I dette pilotprojekt var målet at få viden om, hvorvidt det er muligt at automatisere denne kontrol.
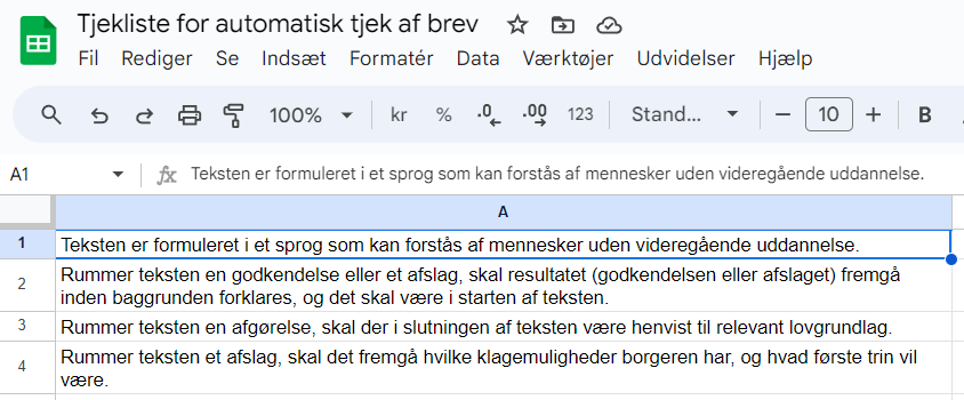
Vi har derfor oprettet et regneark, der rummer en tjekliste, som vores AI skal bruge:
I vores tekstbehandlingsværktøj (her Google Docs) har vi indlejret et værktøj, som snakker sammen med AI (ChatGPT).
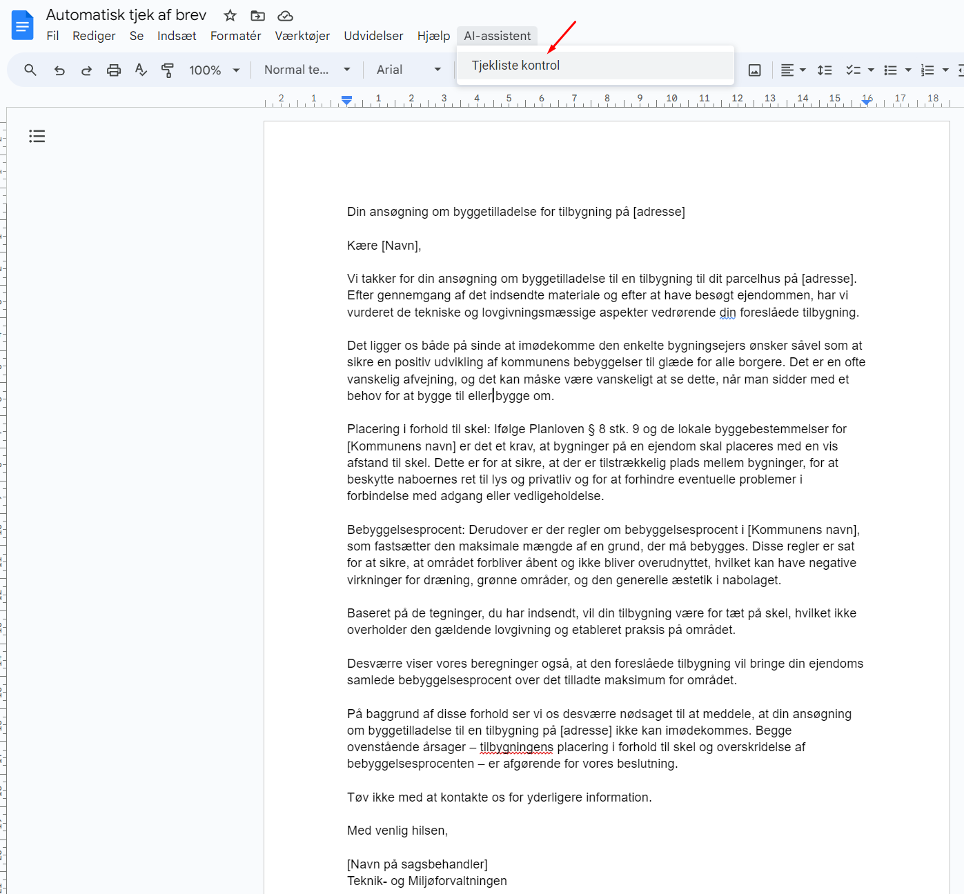
Når vi aktiverer værktøjet, får vi feedback fra værktøjet om, hvorvidt vi overholder kravene i tjeklisten:
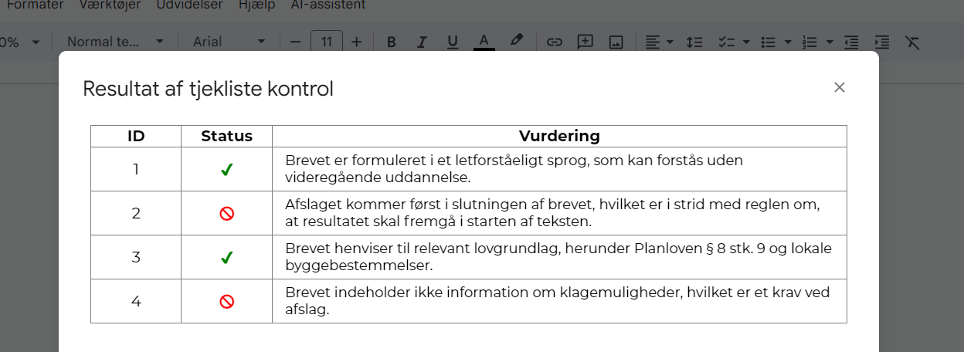
Bruger vi nu en anden brevtekst, der er mere akademisk og snørklet, bliver det problem identificeret effektivt:

Godt resultat – dog ikke i første skud
Selvom vi opnåede et godt slutresultat, viser pilotprojektet et behov for at arbejde iterativt, inden tjeklisten fungerer tilstrækkeligt godt. Det betyder mere konkret, at instrukserne skal finjusteres.
Det er er afgørende, hvordan punkterne i tjeklisten formuleres. Eksempelvis rummer tjeklisten et punkt om at afslag/godkendelse skal stå i starten af brevet. Dette formulerede vi som: ”Rummer teksten en afgørelse, skal afgørelsen fremgå af den første del af teksten.”
Dette fungerede ikke: vores AI rapporterede at dette var overholdt, selvom svaret var gemt nede i midten af brevet. Vi ved ikke, hvorfor den ikke kunne kende ordentligt forskel på, hvad der er henholdsvis starten og midten af brevet.
Vi skærpede derfor formuleringen: ”Rummer teksten en godkendelse eller et afslag, skal resultatet (godkendelsen eller afslaget) fremgå inden baggrunden forklares, og det skal være i starten af teksten.”
Da blev rapporteringen træfsikker.
Valget af AI-model kan påvirke kvaliteten
Vi startede med at bruge AI-modellen ChatGPT i version 3.5. Imidlertid oplevede vi nogle problemer, hvor den rapporterede forkert på et af tjeklistepunkterne. Da vi skiftede til ChatGPT version 4, forsvandt problemet.
Der er forskel på pris på de to modeller, men i vores pilotprojekt har det minimal betydning. Det kan dog gøre en forskel, hvis du vil behandle mange tusinde dokumenter.
Konklusion: AI-teknologien kan hjælpe med ESDH-opgaver
Med de to pilotprojekter ville vi afdække, om AI kan automatisere nogle af de tidskrævende ESDH-opgaver. Vores konklusion er, at det kan teknologien godt. Faktisk giver den massive forretningsfordele, fordi den sparer os for mange timers arbejde.
Fordelene skal dog opvejes i forhold til følgende:
- De fleste ESDH-systemer rummer kun begrænset integration til AI-services som fx ChatGPT. Det betyder, at du selv skal afholde udgiften til at bygge systemerne (ESDH og AI) sammen.
- Det er en iterativ proces at automatisere ESDH-opgaver med AI. Særligt udformningen af AI-instruktioner (”prompts”) kræver finjustering.
- Teknologien er stærk, men du skal stadig overvåge den. Altså skal der være en menneskelig godkendelse af det, som AI producerer – fx forslag til metadata for en sag.
Teknologien har derfor – på sit nuværende stadie – stor berettigelse som en ESDH-assistent, når der er tilstrækkeligt stor volumen i opgaverne, og under forudsætning af at ESDH-systemet tillader smidig integration til andre systemer.
Værdien af læring om AI
Teknologien bliver bedre de kommende år, og den vil forandre hvilke kompetencer, der er brug for som ESDH-medarbejder. Det bliver en vigtig evne at kunne se kritisk på både mulighederne med AI og spotte, når AI tager fejl eller trækker sagsbehandlingen i en uønsket retning. Derudover er det vigtigt at være med til at korrigere AI-værktøjerne.
Ved at få erfaringer med AI i forbindelse med ESDH kan medarbejderne opnå værdifulde erfaringer, som både stiller den enkelte og virksomheden stærkere på den lange bane.

Sådan skaber din virksomhed en sikker og velinformeret AI-assistent
Dette white paper giver dig indsigt i nogle af de fordele, din forretning kan få ved at implementere egen AI-assistent og en trin-for-trin guide til, hvordan du gør i praksis.
Skal vi hjælpe dig med at gennemføre et pilotprojekt?
Vil du gerne i gang med at bruge AI til at automatisere ESDH-/ECM-opgaver? I så fald anbefaler vi, at du starter med at teste teknologien af i din egen kontekst. Dermed får du klarhed over, hvor effektivt den vil kunne fungere.
Vi vil naturligvis gerne hjælpe dig med at gennemføre et pilotprojekt. Er det interessant for dig, er du velkommen til at kontakte os, så vi kan tage en snak om, hvordan I bedst griber det an.

