
Today, we’re going to talk about data collection in European football.
Now, let’s go back to the year 2008. Back then, scouts would spend countless hours travelling the world, watching games, and taking notes on players’ abilities. They would then bring this information back to their team, where it would be analyzed and used to make decisions about which players to sign.
Today, I went to Data.World and collected almost 10 years worth of data.
Screenshot of the link destination for 333 MB of football data
Now I don’t claim to reinvent the wheel here, but access to data like this was groundbreaking at the time it was first done, providing stats on things like passes, shots, and tackles, as well as more advanced metrics like expected assists.
The data prep and load process
Now me being a data engineer, and wanting to use my preferred set of tools, and later wanting to share progress with my co-workers, I could not “just” make use of the SQLite database that was in the downloaded zip – even though it opens natively (and very fast!) in TablePlus.
From TablePlus I exported sets of SQL statements for moving the smaller files:

Export of SQL insert statement from TablePlus
…as well as exporting larger tables to JSON files. I just wanted to test some load performance, while sitting in a couch using wireless data transfer.
Utilising Snowflake, I wanted to compare the execution speed of SQL statements using SnowSight, SnowSQL executing a prepared file with insert statements and lastly a PUT command transferring the JSON to an internal Snowflake stage.
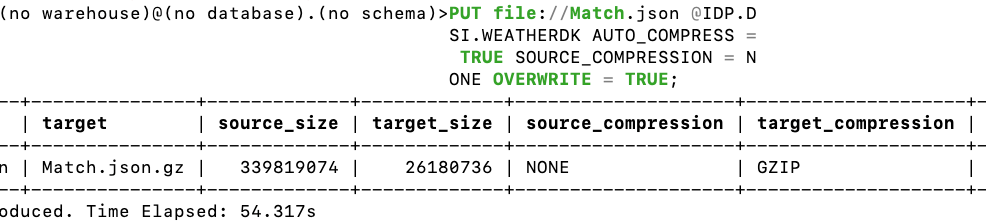
SnowSQL put command from terminal and the result of upload + compression
Some quick learnings:
- The simplest way is the ol’skool command line, here using SnowSQL with a prepared query. (see above screenshot)
- SnowSight data insert speed have improved! Earlier on Snowflake web interfaces had issues with inserts.
- Loading larger data files to an internal stage, is often the optimal way, if data is not available from cloud storage. (13x less size for the JSON here!)
The reason why 1 & 2 does not work for larger amounts, is that you might not even be able to edit a large SQL file holding the query before execution, due to issues with memory or applications on the local machine.
And i assume we can all agree that 13 times less data size is also nice.
Data are now available in Snowflake, some of them in table format other in stage as JSON files, that require content parsing to become available for analysis.
The data definition and manipulation from SQLite to Snowflake
Even though scripts were outputted from SQLite, and from documentation that particular syntax of foreign key definition is not mentioned by Snowflake, then the table creation worked almost without editing (apart from some ´ ` that had to change to ” ). This shows the power of the standardized SQL language:

Table definitions for creating logical objects and for loading data from the internal stage, I wanted at least an ID as well as each JSON object in variant column data type. It really is as simple as:
CREATE OR REPLACE FILE FORMAT JSON_AUTO
TYPE = JSON
COMPRESSION = AUTO
TRIM_SPACE = TRUE
STRIP_OUTER_ARRAY = TRUE
;
DROP TABLE IF EXISTS “Soccer_Match_JSON”;
CREATE OR REPLACE TABLE “Soccer_Match_JSON” (“match_json” VARIANT, ID integer);
COPY INTO “Soccer_Match_JSON” FROM
(SELECT $1::VARIANT as “match_json”
, $1:”id”::INTEGER as ID
FROM @INTERNALSTAGENAME/Match.json.gz
(FILE_FORMAT => JSON_AUTO) );
I did also parse the JSON content into columns, still easy enough using the exact same tools as above – but a long, repeated list since count(“columns”) > 100;
But after this, data is in a relational format, easy for my analytics colleagues to work with, while showcasing SQL, JSON and in the end also the XML capabilities of Snowflake as a platform.
If you are regular to work with databases, but find semistructured to require a special toolset – then try out this small exercise here!
This loaded European football data from 2008-2016 into an easy-to-work with platform making data ready for analysis, and preparing analyst to create insight, based on historical facts.
As you probably know, gone are the days when pundits would simply offer their subjective opinions on players and teams. Now, they need to back up their arguments with hard data and statistics – this is where this walkthrough can help.
Hopefully soon, me or one of my Devoteam Data Driven colleagues will follow this post up with a next chapter, where we analyse or produce new content based on the loaded data content. I see both predictive analyses, as well generative models to be able to base output on the prepared data model.
All of this data availability has been a game-changer for football teams. But it’s not just about scouting and player selection. Teams can now use data to predict how a player is likely to evolve over time. By analyzing factors such as age, playing time, and injury history, they can predict how a player’s performance is likely to change in the coming years. This can help teams decide whether to invest in a player long-term, or whether to sell them while their value is still high.
And I don’t even like football that much, but the related data prep is fun 😀
You can always get in touch with us to know more about how can we help you turn your data insights into business impact.

