Af Frederik Helweg-Larsen, Partner, Devoteam Cyber Trust
Det er ofte helt uklart, hvad der overhovedet menes med IT-beredskab, når man har en dialog om emnet. Mange steder blander man rundt i forskellige termer og definitioner, og det bliver heller ikke nemmere af, at de forskellige standarder også bruger termerne forskelligt.
For at adressere denne forvirring har vi i Devoteam udarbejdet en model, der klarlægger elementerne i beredskabet.
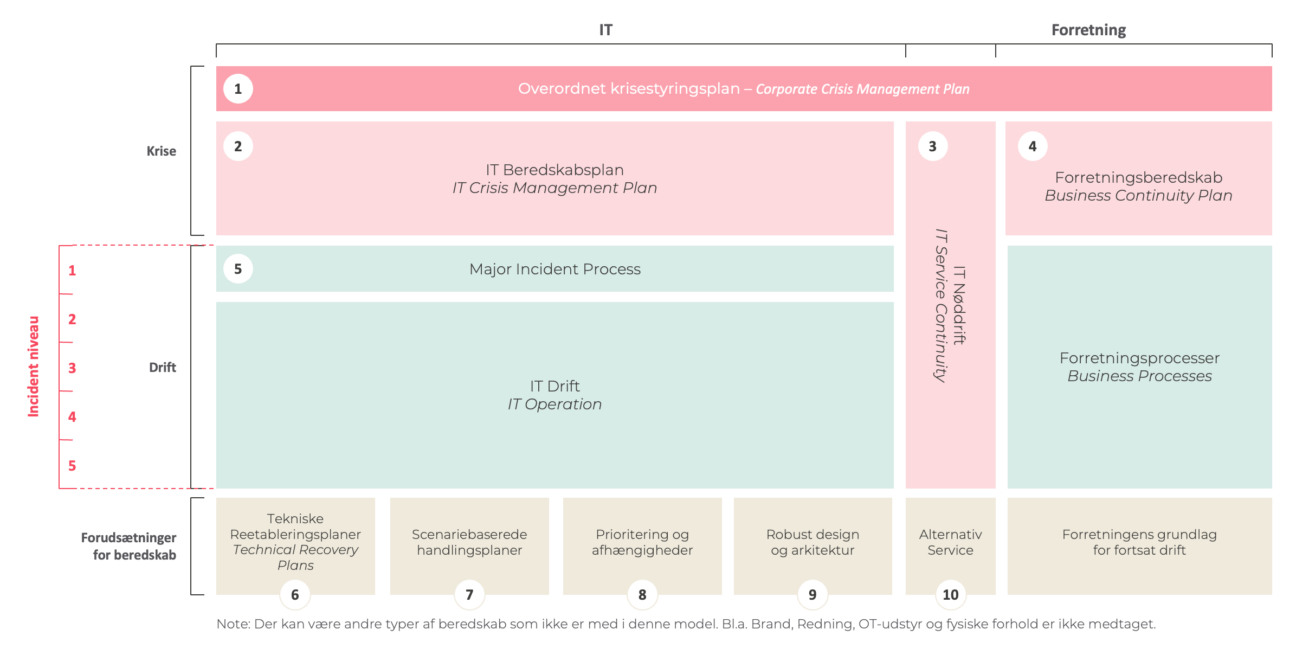
I det følgende gennemgår vi modellen – og vi starter fra bunden.
Forudsætningerne for et godt beredskab
I bunden af vores model finder vi virksomhedens grundlæggende forudsætninger for, at et IT-beredskab ikke blot er en organisatorisk øvelse, men en praktisk anvendelig plan.

Dette fundament bør bestå af følgende:
6. Tekniske reetableringsplaner (Technical Recovery Plans/Disaster Recovery Plans)
Disse planer angiver en konkret trinvis opskrift på, hvordan man reetablerer et system og hvilke forudsætninger, såsom licenser, backup, rettigheder m.m., der er nødvendige for at gennemføre reetableringen.
Planerne skal kun indeholde de essentielle oplysninger, som er nødvendige for reetablering, og skal ikke forveksles med systemdokumentation. Hvis I får brug for ekstern konsulentbistand til reetableringen, så skal denne plan indeholde de oplysninger, som konsulenten har behov for, for at kunne udføre arbejdet.
Planerne skal naturligvis placeres et sted, hvor man stadig kan komme til dem, selv hvis infrastrukturen er utilgængelig. Disse planer anvendes også under almindelige driftsnedbrud, hvor systemer skal genskabes, og er altså ikke forbeholdt en krise.
7. Scenariebaserede handlingsplaner
For at imødegå et forudsigeligt scenarie, som vil påvirke flere systemer samtidig, kan man beskrive et handlingsmønster, der er godt til den specifikke situation. Det er det, du ser i en førstehjælpsbog, hvor der er en sekvens af handlinger, som er forskellige for f.eks. brandsår og drukneulykker.
En typisk handlingsplan kunne være for ransomware angreb, der beskriver et aftalt reaktionsmønster med specifikke forberedte handlinger for at undgå en eskalering af situationen. Den kan f.eks. beskrive, hvordan et netværk hurtigt opdeles i segmenter (også kaldet ø-drift), eller dele af netværket lukkes ned.
En scenariebaseret handlingsplan kan automatiseres som scripts, der udfører handlingerne hurtigt, da reaktionen skal kunne gennemføres inden for få minutter. Der bør være ledelsesmæssig godkendelse af disse planer, da de ofte påvirker virksomhedens aktiviteter dramatisk, og vil iværksætte en eller flere forretningsmæssige beredskabsplaner.
8. Prioritering og afhængigheder
Hvis systemer skal reetableres, så vil det ske efter et ”kø-system”, som IT-afdelingen driver. Her reetablerer man først IT-infrastruktur og derefter de systemer, som er en forudsætning for, at resten af systemerne kan fungere. Forretningen kan ud fra deres prioritering af systemernes vigtighed bede om at få reetableret i en bestemt rækkefølge, der kan forberedes.
Det gøres ofte på baggrund af en vurdering af de forretningsmæssige konsekvenser (betegnes Business Impact Assessment, BIA). Det er en forudsætning for, at man tager fat i de vigtigste systemer og services først, og at kritiske forretningsgange hurtigst muligt bliver reetableret.
Da der ofte er flere forretningsområder, så skal de ansvarlige for forretningsområderne blive indbyrdes enige om deres prioriteringer, så der ikke er interne konflikter i en beredskabssituation. Denne rækkefølge kan naturligvis ændres i situationen, men det er langt hurtigere end at starte uden noget.
Afhængigheder mellem systemer og services kan være sværere at afdække, hvis man ikke har en meget vedligeholdt CMDB (Configuration Management Database). Hvis det ikke er velbeskrevet, så er det en fordel at udarbejde nogle enkle skitser, som viser grundlæggende afhængigheder, da det hjælper med at træffe beslutninger i en krise, og påvirker rækkefølgen af reetableringen.
9. Evnen til at reetablere systemer eller fortsætte med en redundant drift
Et robust design af systemer og arkitekturer kan reducere en del af de problemer, der er forårsaget af nedbrud eller cyberangreb. Der skal være en balance mellem systemets kritikalitet og designets robusthed, hvilket ofte er en økonomisk overvejelse, da det er kostbart at have redundante systemer. Eksempler på robust design er redundante systemer, dublerede services, segmenteret netværk, backup designet til krise-reetablering og anvendelse af cloud-services, som kan køre uafhængigt af on-premise systemer.
10. Alternative Services er IT-funktionens plan B
De forretningsmæssige beredskabsplaner vil beskrive de ønsker, der er til nøddrift, og dette bygger på nogle alternative services, som skal fungere i hverdagen, så de er klar i krisen. Det kan være en alternativ kommunikationsplatform eller daglige datadumps, som kan sikre forretningens fortsatte drift. Disse services kan være ”sovende” indtil, der er behov for dem, og skal igen være uafhængige af eget netværk. Dette svarer til, at man før i tiden printede lister ud hver dag, så de kunne bruges i en krise. Det kan man stadig, men tiden er løbet lidt fra denne tilgang, da det er for ressourcekrævende, og ofte ikke løser alle de behov, man har.
Den daglige drift
De blå felter er de områder, der hører til virksomhedens daglige drift. Hele dette område har det formål at sørge for, at en hændelse ikke udvikler sig til en krise.

5. Driftsdelen
Driftsdelen består af:
- Forretningsprocesser er den almindelige forretningsdrift. Hvis den bliver udfordret, kan man iværksætte de forretningsmæssige beredskabsplaner (Business Continuity).
- Processer for almindelige hændelser (Incident Process) er et almindeligt og ofte lokalt problem. Det kan eksempelvis være, at en medarbejders computer ikke fungerer.
- Processer for store hændelser (Major Incident Process) kan eksempelvis være, når mange computere i selskabet ikke fungerer, eller flere kritiske systemer er ramt.
I venstre side af modellen kan du se en skala fra 1-5. Det er en skala for hændelsens alvorlighed, hvor 1 er det mest kritiske. Det mest alvorlige i en IT-driftsorganisation betegnes Major Incident. En eller flere Major Incidents vil ofte trække på alle de ressourcer, som en IT-afdeling har til rådighed, og betyde at det normale serviceniveau falder mærkbart.
Når der sker en alvorlig hændelse, så går IT-afdelingen straks i gang med at prøve at løse problemet med alle tænkelige midler. Kan det ikke lade sig gøre, så trykkes der på knappen og beredskabsledelsen går ind og overtager krisestyringen. Det sparer tid at varsle beredskabsledelsen ved alle major incidents.
Det vil typisk være en IT-chef i virksomheden, der har IT-kriseleder-rollen, og dermed beslutter om, der er en beredskabssituation.
Krisestyring og beredskabsledelse
De øverste røde felter i vores model handler om den del af beredskabet, som indløses i det sekund en hændelse er gået over og er blevet en krise.

I dette ligger områder som:
2. IT-kriseledelse (IT Crisis Management)
Dette er IT-afdelingens kriseledelse, og er et lag ovenpå Major Incident-arbejdet. Her køres der et war-room med en klar rollefordeling og struktureret ledelse. Der tilføres ofte flere ressourcer og iværksættes beslutninger med et forberedt mandat. Det er her det store overblik holdes, og der vil ofte være roller her som HR, Kommunikation, Koordinering, Forretningsledelse og Faciliteter.
Her koordineres de langsigtede indsatser, som prioriteres og kommunikeres til alle interessenter. IT-kriseledelsen kan indhente støtte fra specialister udefra til at håndtere situationen, og tager også ansvar for de afvigelser, der vil være til politikker og retningslinjer.
3. IT-nøddrift (IT Service Continuity)
Dette er for mange et næsten ukendt begreb, og kan kun defineres og iværksættes i tæt samarbejde med forretningsledelsen. Nøddrift er ikke det samme som redundans, men vil ofte være alternative systemer eller dataudtræk, som gøres tilgængelige på andre måder. Det kan være et regneark, der er klar til at erstatte kvalitetsstyringssystemer, hvis de går ned.
Det er ofte få data, der er behov for, til at lede sin virksomhed videre i en krise, men det er enormt vigtige data. Det kan godt være, at man kan udlevere varer fra et lager med kuglepen og en blok, men det vil tage rigtig lang til at få disse data importeret, når systemerne er tilbage. Derfor er en alternativ digital løsning ofte bedre.
4. Forretningsberedskab (Business Continuity)
Disse planer beskriver, hvordan virksomheden kører videre, hvis man pludselig står uden sine IT-systemer eller andre afgørende ressourcer. Planerne udarbejdes ikke af IT-afdelingen, men af medarbejderne, som kender arbejdsprocesserne. De kender deres eget områdes daglige rutiner, behov og regler. Det er ofte dem, der er ansvarlige for processer og forretningsområder, som står for udarbejdelsen af de forretningsmæssige beredskabsplaner.
Ofte bliver business continuity brugt som en paraply-beskrivelse for beredskab. Men det er bare ét område af det samlede beredskab, og uanset hvad du kalder det, så vær specifik.
1. Overordnet krisestyring (Corporate Crisis Management)
Dette er hele organisationens kriseledelse. Hvis IT er nede, kan det trække hele virksomheden ned, og så er hele virksomheden i krise. Så løser IT-kriseledelsen, med IT-direktøren i spidsen, IT-krisen, mens den overordnede kriseledelse varetages her. Her er det oftest CEO’en, der sidder som kriseleder.
Denne plan er ikke afgrænset til IT-hændelser, men kan også rumme krig, ekstremt vejr, pandemier og lignende. Dog vil en IT-beredskabshændelse meget ofte aktivere hele virksomhedens beredskab, og derfor er det vigtigt, at der er et tæt og velfungerende samarbejde mellem de to krisestabe.
Test af beredskabsplanerne
Alle planerne bør testes regelmæssigt med scenarier, som er realistiske og udfordrende. Planerne skal testes individuelt for at gøre afprøvningen så konkret som mulig.
Det er en god idé at udarbejde en testplan, som strækker sig over tre år, da det ofte ikke er muligt at teste alle planer inden for 12 måneder.
Afprøvningen af planerne skal være tilpasset et specifikt formål og have et passende ambitionsniveau. Det er vigtigt, at der kommer konkret læring ud af afprøvningerne, og derfor kan man med fordel lægge en testplan, som stiger i kompleksitet i takt med, at man bliver bedre. Det kunne være i disse trin:
- Peer-review af planen. Hvis dine kollegaer ikke forstår planen, så skal den sikkert rettes til. Planen læses igennem og tilpasses af en med tilstrækkelig faglig viden.
- Scenariebaseret simulering. Planen afprøves i en simuleret hændelse, som er tilpasset virksomheden. Handlinger begrænses til at være beskrivende og iværksættes ikke.
- Teknisk afprøvning. Her prøves de dele af planen af, som ikke vil påvirke virksomhedens drift negativt. Det kan være en test af SMS-krisekommunikation, det kan være failover af enkelte redundante systemer eller kontakt til leverandører.
- Drift afprøvning. Her prøves et scenarie af så tæt på virkeligheden som muligt. Systemer reetableres, samarbejdspartnere kontaktes og medarbejdere kan endda evalueres som en del af en brandøvelse. Dette er forbundet med væsentlige omkostninger og risici, og planlægges derfor grundigt i god tid forinden. Ofte vil elementerne i en live afprøvning være testet på niveau tre, inden de medtages i øvelsen.
Gode råd – og de menneskelige aspekter i beredskabsplanlægningen
Når en krise opstår, er det oftest nødvendigt at styre slagets gang med et militært mindset.
Der skal løbes stærkt. Beslutninger skal tages med hård og hurtig hånd, og medarbejderne bliver nødt til at yde en ekstra indsats. Derfor skal man også have et øje på det menneskelige aspekt i krisen.
Ofte bliver folk gennem et angreb presset meget hårdt over lang tid, måske døgnet rundt, og derfor kan de ikke mere på et tidspunkt. HR-funktionen vil spille en vigtig rolle i at varetage medarbejdernes trivsel og forebygge stress og dårligt arbejdsklima. Det er også vigtigt at huske på, at de fleste medarbejdere ikke har en kontraktlig forpligtigelse til at arbejde ekstraordinært i en krise, og derfor skal håndteres med omtanke.
Demant og Mærsk er eksempler på virksomheder, hvor et cyberangreb ramte og varede i flere måneder, og hvor nogle systemer aldrig kom til tilbage. Medarbejderne glemmer heller ikke, hvor hårdt det var at være en del af hændelsen, og håndteringen bliver en del af virksomhedens fremtidige image.
Læg ikke skinneren mens toget kører
Det bør være selvsagt, at beredskabet skal være etableret, inden et cyberangreb opstår. At bygge sit beredskab tager tid, og dét har du ikke meget af, når du bliver angrebet.
Den tid der lægges i forberedelse og udarbejdelse af planer, den tages direkte ud af tiden til reetablering efter et cyberangreb. Det er ofte svære beslutninger, som skal træffes under et voldsomt tidspres, og det er bedre at have taget disse diskussioner, inden hændelsen indtræffer. På den måde kan tempoet under et cyberangreb sættes op, og der er mindre utryghed, da man kan holde sig til nogle kendte rammer.
Hvis du vil søge inspiration til et godt beredskab, så se i retning af Forsvaret, Redningsberedskabet eller Almindelig førstehjælp. Her er metoder, som er afprøvet i livstruende situationer og tilpasset gennem generationer. Brug deres operationelle erfaringer, og læg mærke til, hvor enkelt og kortfattet metoderne ofte er.
Anbefalinger til inspirerende læsestof:
- The Checklist Manifesto, Atul Gawande
- Battle Mind. At præstere under pres, Merete Wedell-Weddelsborg
- Almindelig førstehjælp, Sundhed.dk
- Forsvarets 5 punkts befaling, Forsvarsakademiet.
Se også vores webinar om beredskab
Se vores on-demand webinar, Beredskab i samfundsvigtige funktioner, hvor du kan blive klogere på, hvordan du sikrer og optimerer beredskabsplanerne i din virksomhed. Få også et indblik i de konkrete aktiviteter og elementer, som sikrer en god vedligeholdelse af din beredskabsplan.
Har du øvrige spørgsmål til, hvordan du som virksomhed bedst muligt kan sikre driften mod uforudsete trusler, er du velkommen til at række ud til Frederik Helweg-Larsen, Partner i Devoteam Cyber Trust, på fhl@devoteam.com.

